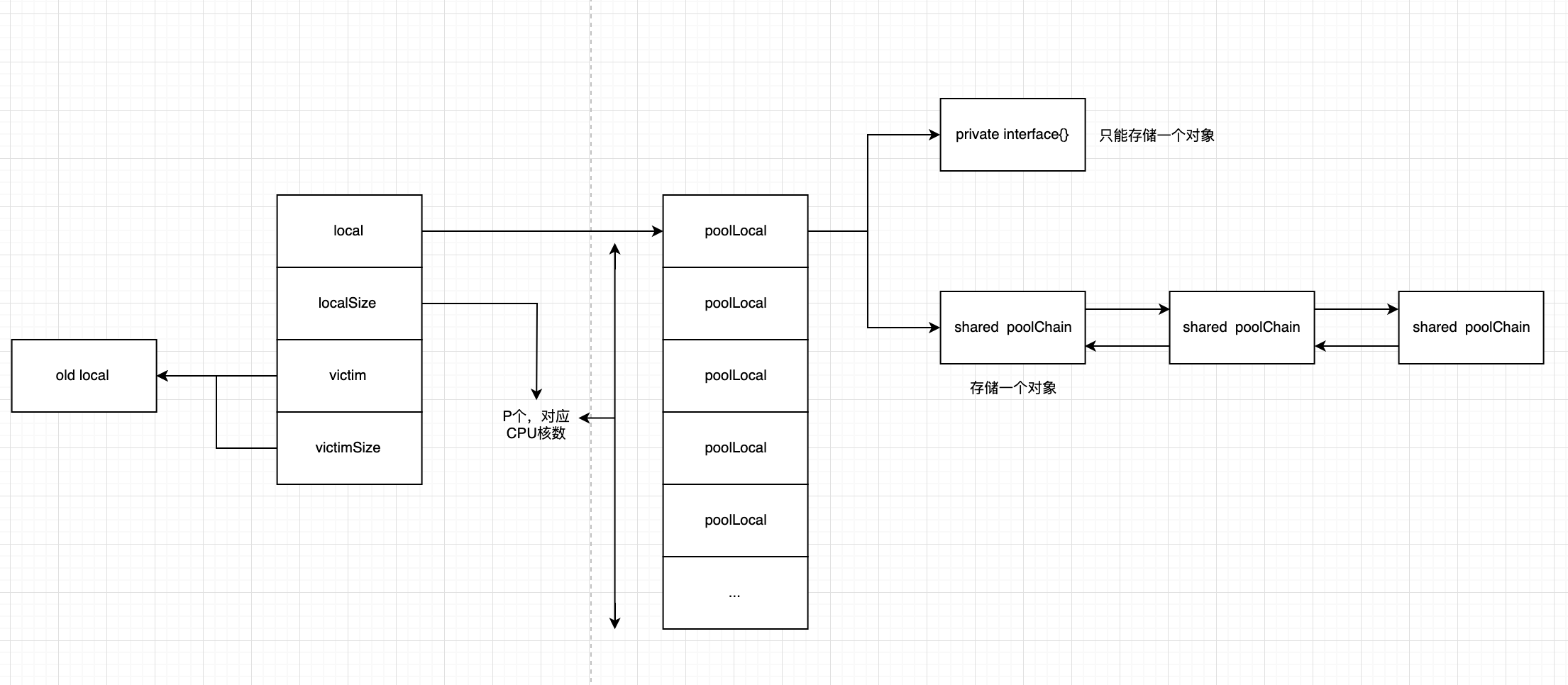
local unsafe.Pointer // local fixed-size per-P pool, actual type is [P]poolLocal localSize uintptr// size of the local array
victim unsafe.Pointer // local from previous cycle victimSize uintptr// size of victims array
// New optionally specifies a function to generate // a value when Get would otherwise return nil. // It may not be changed concurrently with calls to Get. New func()interface{} }
func(p *Pool)Get()interface{} { ... l, pid := p.pin() x := l.private if x == nil { // Try to pop the head of the local shard. We prefer // the head over the tail for temporal locality of // reuse. x, _ = l.shared.popHead() if x == nil { x = p.getSlow(pid) } } ... if x == nil && p.New != nil { x = p.New() } ... }
首先通过p.pin()获取当前goroutine绑定的P,以及P对应的poolLocal
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
// pin pins the current goroutine to P, disables preemption and // returns poolLocal pool for the P and the P's id. // Caller must call runtime_procUnpin() when done with the pool. func(p *Pool)pin()(*poolLocal, int) { pid := runtime_procPin() // In pinSlow we store to local and then to localSize, here we load in opposite order. // Since we've disabled preemption, GC cannot happen in between. // Thus here we must observe local at least as large localSize. // We can observe a newer/larger local, it is fine (we must observe its zero-initialized-ness). s := atomic.LoadUintptr(&p.localSize) // load-acquire l := p.local // load-consume ifuintptr(pid) < s { return indexLocal(l, pid), pid } return p.pinSlow() }
func(p *Pool)getSlow(pid int)interface{} { size := atomic.LoadUintptr(&p.localSize) // load-acquire locals := p.local // load-consume // Try to steal one element from other procs. for i := 0; i < int(size); i++ { l := indexLocal(locals, (pid+i+1)%int(size)) if x, _ := l.shared.popTail(); x != nil { return x } } ... // Try the victim cache. We do this after attempting to steal // from all primary caches because we want objects in the // victim cache to age out if at all possible. size = atomic.LoadUintptr(&p.victimSize) ifuintptr(pid) >= size { returnnil } locals = p.victim l := indexLocal(locals, pid) if x := l.private; x != nil { l.private = nil return x } ... }
// Put adds x to the pool. func(p *Pool)Put(x interface{}) { if x == nil { return } if race.Enabled { if fastrand()%4 == 0 { // Randomly drop x on floor. return } race.ReleaseMerge(poolRaceAddr(x)) race.Disable() } l, _ := p.pin() if l.private == nil { l.private = x x = nil } if x != nil { l.shared.pushHead(x) } runtime_procUnpin() if race.Enabled { race.Enable() } }
funcpoolCleanup() { // This function is called with the world stopped, at the beginning of a garbage collection. // It must not allocate and probably should not call any runtime functions.
// Because the world is stopped, no pool user can be in a // pinned section (in effect, this has all Ps pinned).
// Drop victim caches from all pools. for _, p := range oldPools { p.victim = nil p.victimSize = 0 }
// Move primary cache to victim cache. for _, p := range allPools { p.victim = p.local p.victimSize = p.localSize p.local = nil p.localSize = 0 }
// The pools with non-empty primary caches now have non-empty // victim caches and no pools have primary caches. oldPools, allPools = allPools, nil }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
funcgcStart(trigger gcTrigger) { ... // stop the world, before gc // clearpools before we start the GC. If we wait they memory will not be // reclaimed until the next GC cycle. clearpools() ... }