string
这里关注几个重点API,创建、扩容、释放
数据结构
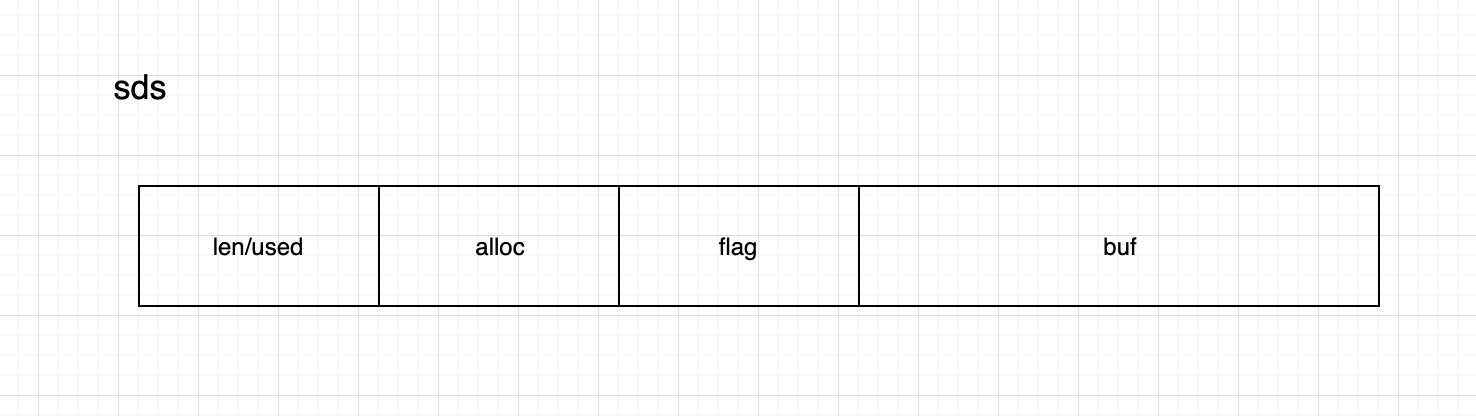
sds是string存储的基本单元
在C语言中,string是以\0结尾,对于本身就包含\0的string来说,会被C语言意外截断,为了解决这个问题,redis采用了保存string长度的方法
redis按照string的长度,划分了5类数据,分别表征$2^5, 2^8, 2^16, 2^32, 2^{64}$的长度
1 |
第二,每种sds,有三个头部信息(SDS_TYPE_5有两个),分别是总长度,已使用的长度,字符串类型
1 | /* Note: sdshdr5 is never used, we just access the flags byte directly. |
每个结构体都是packed的,可以很方便的根据buf,获取到len、alloc、flags等字段
buf地址返回给上层api,完美的兼容C
sdsnewlen
1 | sds sdsnewlen(const void *init, size_t initlen) |
根据initlen,设置成不同的type
创建并初始化sdshdr结构体
- malloc和memcpy字符串
这里,len和alloc都被初始化成initlen,即new的时候,不存在free的数据
sdscatlen
1 | sds sdscatlen(sds s, const void *t, size_t len) |
本质即扩容
- 判断free len是否满足
- 不满足则扩容,新长度小于1M,直接2倍扩容,大于1M,+1M扩容
- 判断扩容后type是否变化,无变化realloc申请,否则malloc
- 扩容完,拷贝拼接,更新sdshdr结构体
sdsfree
1 | void sdsfree(sds s) |
很简单,通过s找到sdshdr结构体的指针,代用zfree释放
总结
sds的数据结构
packed,结构体寻址
如何扩容
< 1M,2倍扩容,> 1M, + 1M
跳跃表(zskiplist)
跳跃表是一种用空间换时间的算法,比红黑树实现简单,效率差不多,其查找的时间复杂度是$O(\log{N})$
核心思想
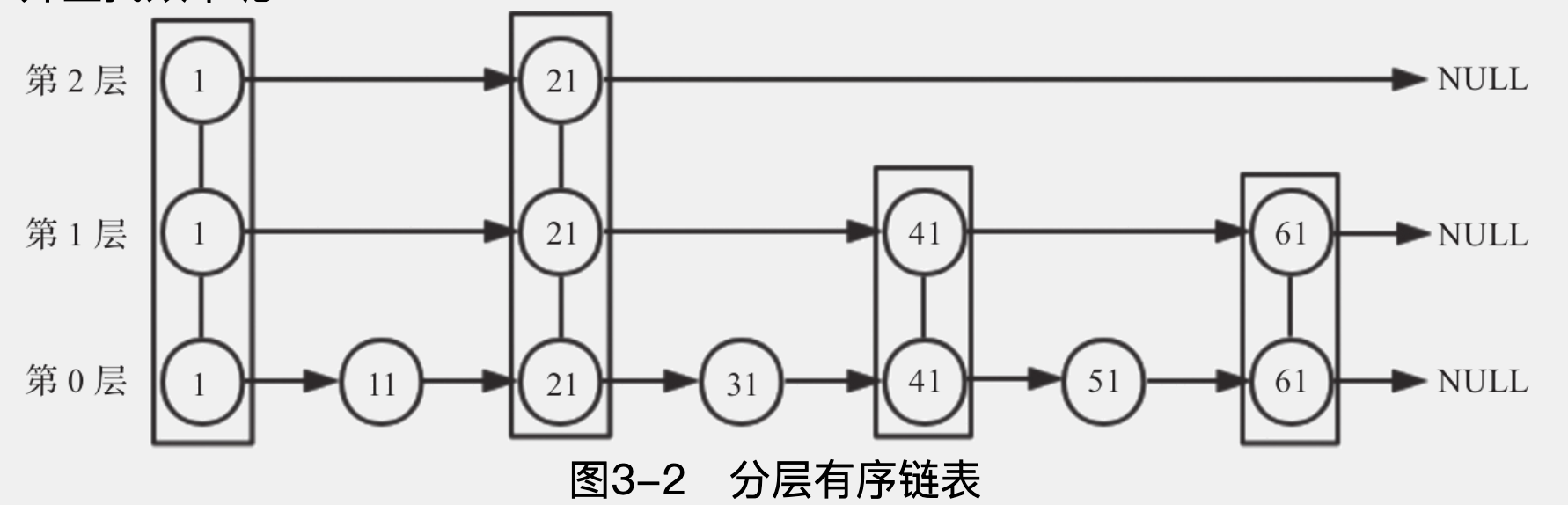
跳跃表通过分层,减少遍历的范围
跳跃表本质上,是一种二分的思想,由于链表在查找上是$O(N)$的时间复杂度,为了降低这个复杂度,通过构建额外的有序链表(存储”二分节点”),来加快遍历
数据结构
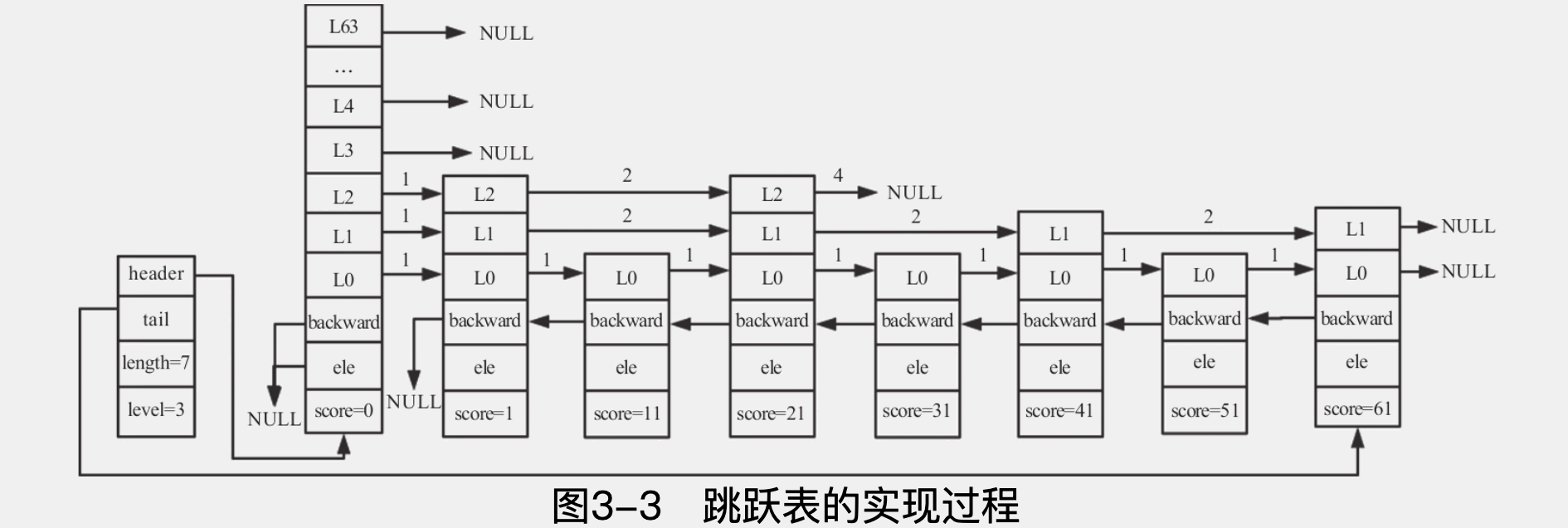
6.0.3里L的高度变成了32,而不是64
上图容易造成一个错觉,L0可能指向下一个L0的地址,实际上,L0的forward指针,指向的是下一个zskiplistNode
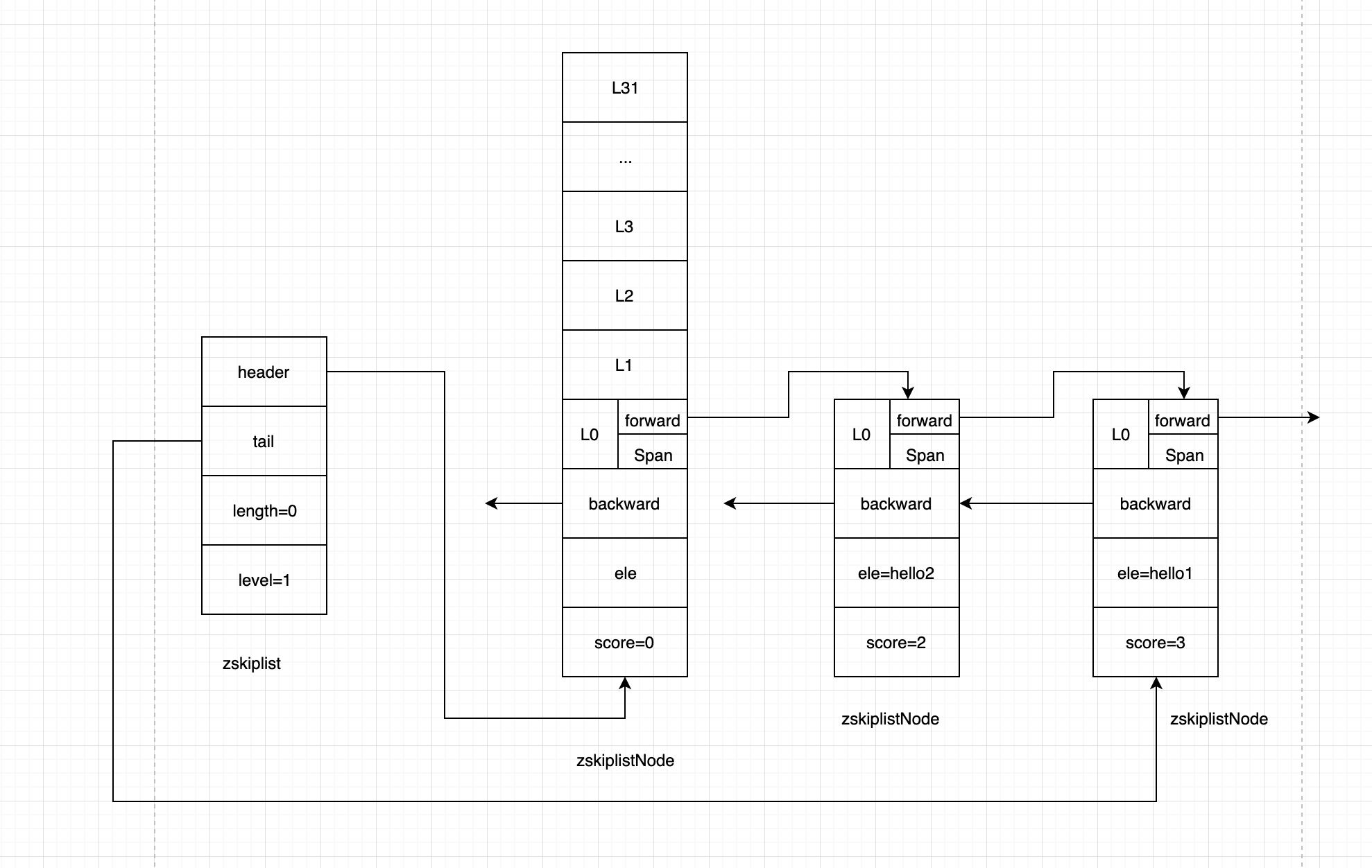
这里有几个重要的数据
zskiplist的level
1
level = max(all len(zskiplistNode.level[]))
zskiplist的length
所有zskiplistNode的个数
zskiplistNode的span
步长的意思,表示和上一个zskiplistNode,中间隔了多少个L0层的node节点
1 | typedef struct zskiplist { |
创建
1 |
|
这个函数比较简单,初始化zskiplist结构体,创建header节点
插入
- 查找要插入的位置
- 调整跳跃表的高度
- 插入节点
- 调整backward
查找
整个查找过程如下图的路径,当发现score <= next node’s score,即转向下一层

1 | x = zsl->header; |
这里使用了两个临时数组update, rank
每次发生level—,即意味着,已经找到了新节点要插入的位置,这时候,把位置节点缓存到update上,把位置节点的span缓存到rank上
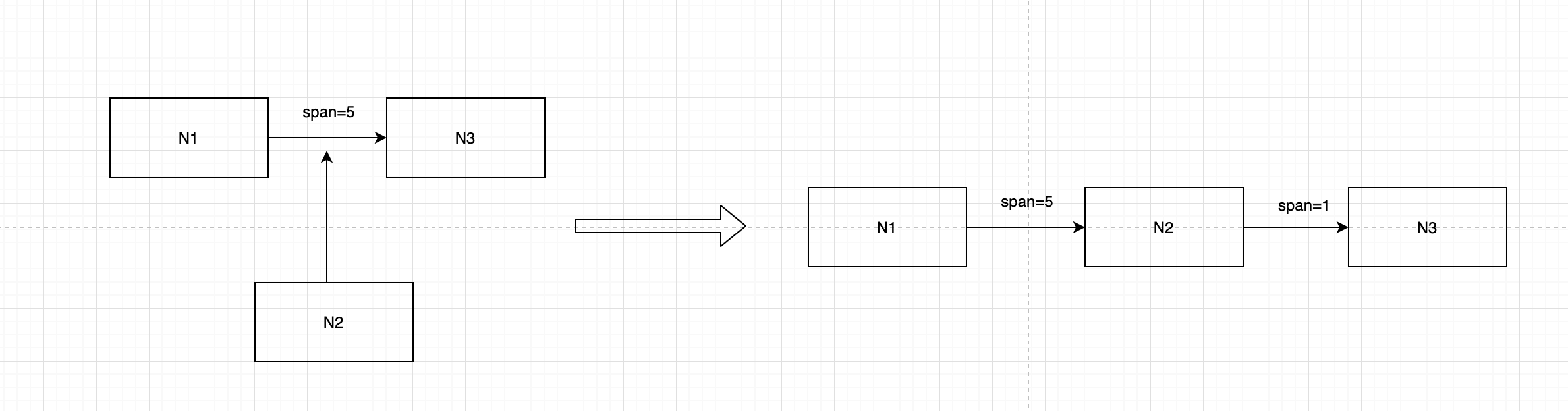
N2占据的N3的位置,N2和N3由于之间没有节点了,所以span=1
创建新节点
创建新节点会随机一个level出来,如果比当前的level大,那么更新zskiplist的level
所以redis更新level是随机的,$level=p^{n-1}(1-p), p = ZSKIPLIST_P=0.25$
level的数学期望是1.33
1 | level = zslRandomLevel(); |
更新节点
把新节点x,插入到各个level中,并且更新span
1 | // x = zslCreateNode(level,score,ele) |
更新backward
下一个节点的backward指向x
1 | x->backward = (update[0] == zsl->header) ? NULL : update[0]; |
删除节点
删除节点,是插入的一个反向过程,同样的查找位置,删除节点,更新前一个节点和后一个节点的forward和backward,以及span
总结
跳跃表主要用于zset(有序集合)的实现
其查询、插入、删除的复杂度都是$O(\log{N})$
扫描二维码,分享此文章