Continuous Bag-of-Word Model(CBOW)
One word
the vocabulary size is V , and the hidden layer size is N
CBOW: input is content words, output is target word
First, let’s see an simple model, one input word, one output word.
for example, two words [‘I’, ‘like’], input is ‘I’, output is ‘like’
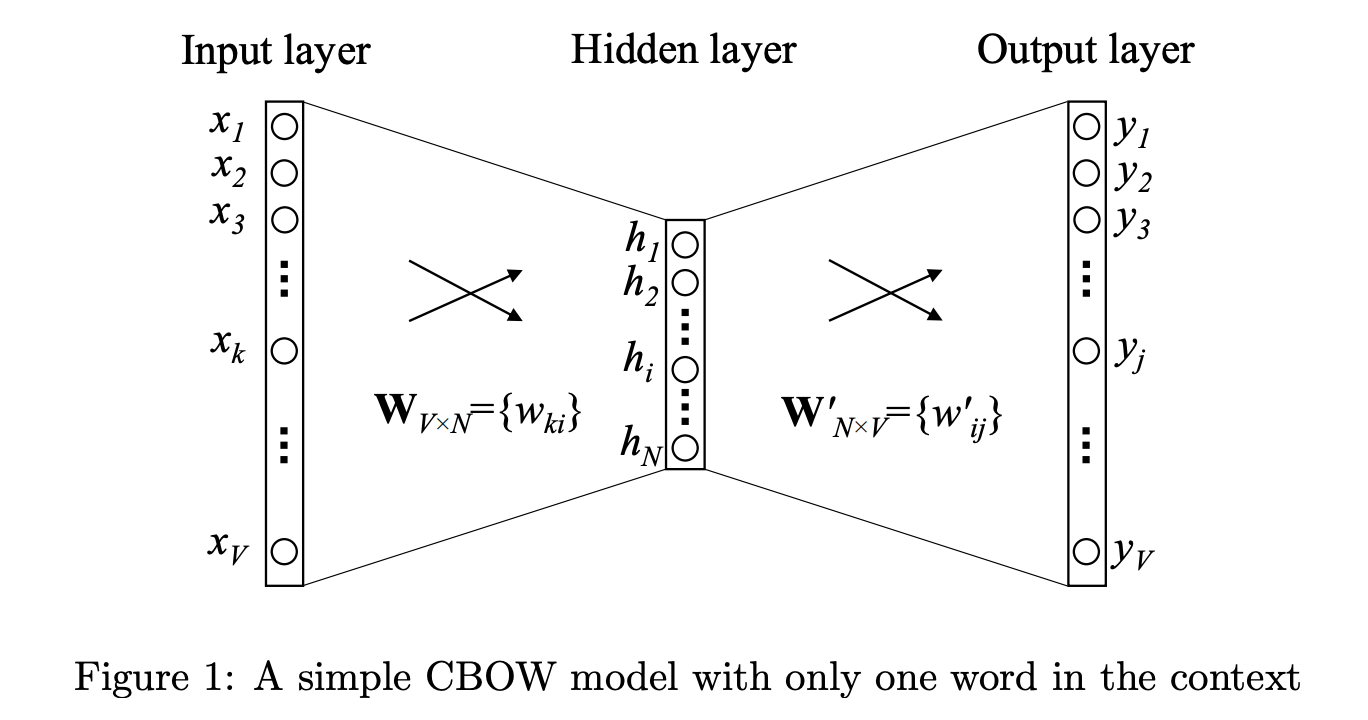
here, we use one-hot encode, ${x_1, x_2…x_v}$, form is $[0,1,…0]$(only one 1)
two weight matrix,$W$ and $W’$
Forward propagation
To get hidden layer:
$\mathbf h$ is $N * 1$ dimension
then we have a output vertor named $\mathbf W’$
$\mathbf u$ is $V * 1$, same as $\mathbf x$
usually, we use softmax to get the probability.
and it is vertor form, if we look at each element’s form of vector, we will get:
here, we know x is one-hot, so $xk = 1, x{k’}=0, k’ \neq k$, and it multiple with $W^T$,
for example:
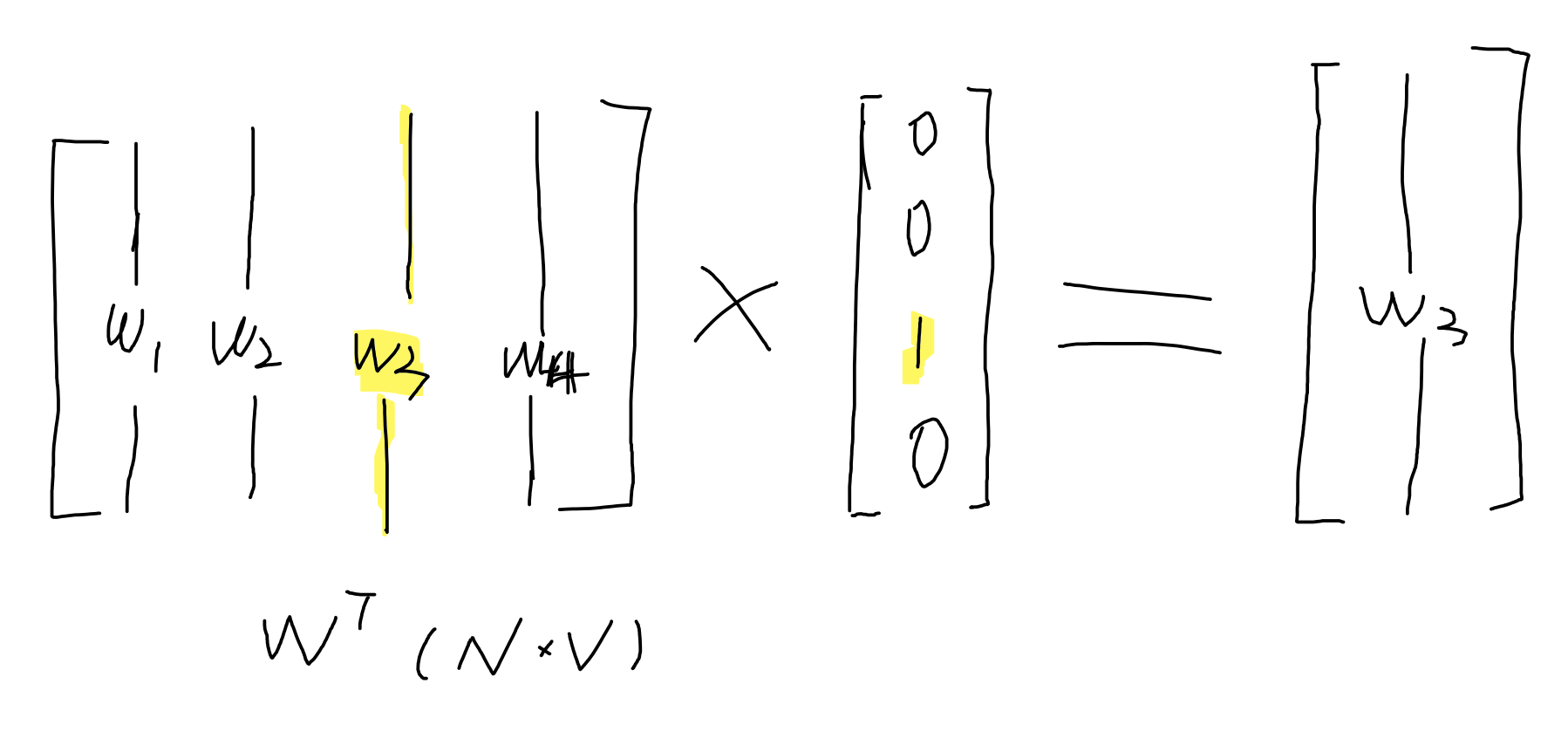
and for $\mathbf u$, each element of $\mathbf u$ should be:
for y:
backward propagation
for hidden-output vector
according maximum likelihood estimation, we want
y_true = [0, 1, 0, 0], y_pred = [0.1, 0.80, 0.01, 0.2], here $j^* = 1, y_{j^*}=0.8$, and we want $\max y_{j*}$
where $E=-\log p\left(w{O} | w{I}\right)$ is our loss function, and we want mininum it.
let’s get its derivative:
here because loss is about $j^$, and derivative is about $j$, so we have $t_j = 1 \ when \ j = j^, else \ t_j = 0$
then go on:
that is good, we can use it in gradient descent
or
for input-hidden vector
for gradient descent
Multi-word context
We use the average
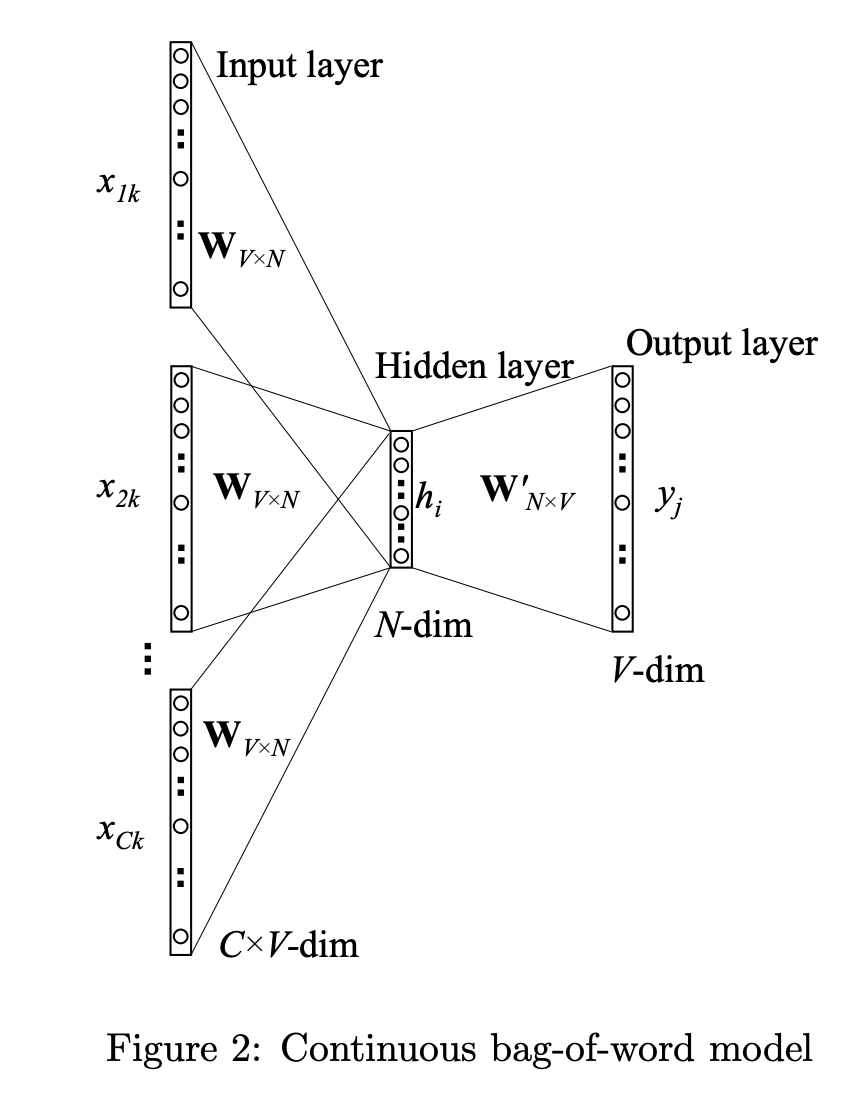
and
Skip-Gram Model
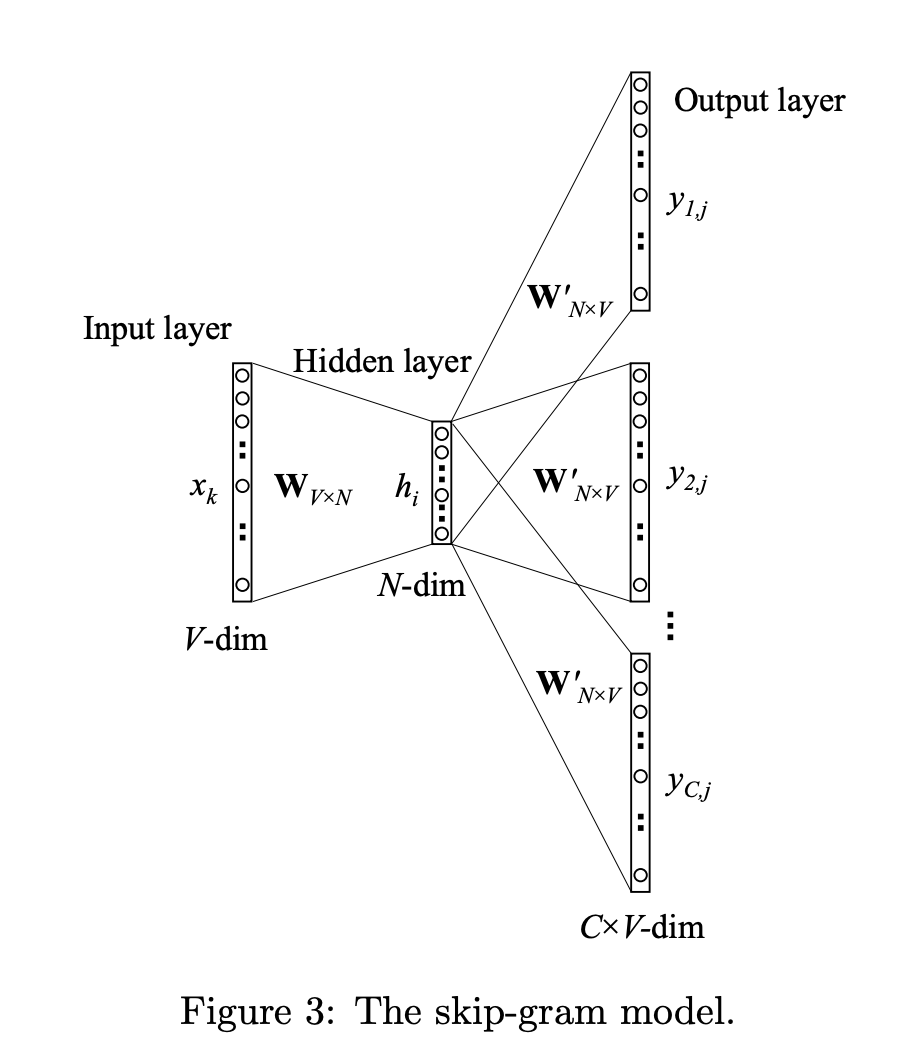
different with CBOW, skip-gram uses one word input and multiple output words.
for example, we have a word with one-hot $[0, 0, 1, 0, 0]$, and have 3 words which is assiociated,
so y will be $[1, 1, 0, 1,0]$
forward propagation
the calculation of input and hidden is same with CBOW.
for hidden to output:
Note: in the Figure 3, we see there is C $W’{N*V}$, but actually they are one $W’{N*V}$,
and why so many y?
for example, like what we say before, the y is [1, 1, 0, 1, 0], for 3 words assiociated, and if we divide it to 3 vector, it is [1, 0, 0, 0, 0], [0, 1, 0, 0, 0], [0, 0, 0, 1, 0],
it explains why we have C output in Figure 3, but they have one shared weight.
backpropagation
For loss, it changed to
For hidden-output vector
and derivative, each word in C
so, sum it:
gradient descent
or
For input-hidden vector
where $\mathbf{EH}$ is an N-dimension vector, each component of which is defined as:
扫描二维码,分享此文章